「react进阶」年终送给react开发者的八条优化建议(篇幅较长,占用20-30分钟)

笔者是一个 react 重度爱好者,在工作之余,也看了不少的 react 文章, 写了很多 react 项目 ,接下来笔者讨论一下 React 性能优化的主要方向和一些工作中的小技巧。送人玫瑰,手留余香,阅读的朋友可以给笔者点赞,关注一波 。 陆续更新前端文章。
本文篇幅较长,将从 编译阶段 -> 路由阶段 -> 渲染阶段 -> 细节优化 -> 状态管理 -> 海量数据源,长列表渲染 方向分别加以探讨。
一 不能输在起跑线上,优化babel配置,webpack配置为项
1 真实项目中痛点
当我们用create-react-app或者webpack构建react工程的时候,有没有想过一个问题,我们的配置能否让我们的项目更快的构建速度,更小的项目体积,更简洁清晰的项目结构。
随着我们的项目越做越大,项目依赖越来越多,项目结构越来越来复杂,项目体积就会越来越大,构建时间越来越长,久而久之就会成了一个又大又重的项目,所以说我们要学会适当的为项目‘减负’,让项目不能输在起跑线上。
2 一个老项目
拿我们之前接触过的一个react老项目为例。我们没有用dva,umi快速搭建react,而是用react老版本脚手架构建的,这对这种老的react项目,上述的问题都会存在,下面让我们一起来看看。
我们首先看一下项目结构。
再看看构建时间。
为了方便大家看构建时间,我简单写了一个webpack,pluginConsolePlugin ,记录了webpack在一次compilation所用的时间。
js 体验AI代码助手 代码解读复制代码const chalk = require('chalk') /* console 颜色 */
var slog = require('single-line-log'); /* 单行打印 console */
class ConsolePlugin {
constructor(options){
this.options = options
}
apply(compiler){
/**
* Monitor file change 记录当前改动文件
*/
compiler.hooks.watchRun.tap('ConsolePlugin', (watching) => {
const changeFiles = watching.watchFileSystem.watcher.mtimes
for(let file in changeFiles){
console.log(chalk.green('当前改动文件:'+ file))
}
})
/**
* before a new compilation is created. 开始 compilation 编译 。
*/
compiler.hooks.compile.tap('ConsolePlugin',()=>{
this.beginCompile()
})
/**
* Executed when the compilation has completed. 一次 compilation 完成。
*/
compiler.hooks.done.tap('ConsolePlugin',()=>{
this.timer && clearInterval( this.timer )
const endTime = new Date().getTime()
const time = (endTime - this.starTime) / 1000
console.log( chalk.yellow(' 编译完成') )
console.log( chalk.yellow('编译用时:' + time + '秒' ) )
})
}
beginCompile(){
const lineSlog = slog.stdout
let text = '开始编译:'
/* 记录开始时间 */
this.starTime = new Date().getTime()
this.timer = setInterval(()=>{
text += '█'
lineSlog( chalk.green(text))
},50)
}
}构建时间如下:

打包后的体积:

3 翻新老项目
针对上面这个react老项目,我们开始针对性的优化。由于本文主要讲的是react,所以我们不把太多篇幅给webpack优化上。
① include 或 exclude 限制 loader 范围。
js 体验AI代码助手 代码解读复制代码{
test: /\.jsx?$/,
exclude: /node_modules/,
include: path.resolve(__dirname, '../src'),
use:['happypack/loader?id=babel']
// loader: 'babel-loader'
}② happypack多进程编译
除了上述改动之外,在plugin中
js 体验AI代码助手 代码解读复制代码/* 多线程编译 */
new HappyPack({
id:'babel',
loaders:['babel-loader?cacheDirectory=true']
})③缓存babel编译过的文件
js 体验AI代码助手 代码解读复制代码loaders:['babel-loader?cacheDirectory=true']
④tree Shaking 删除冗余代码
⑤按需加载,按需引入。
优化后项目结构

优化构建时间如下:

一次 compilation 时间 从23秒优化到了4.89秒
优化打包后的体积:

由此可见,如果我们的react是自己徒手搭建的,一些优化技巧显得格外重要。
关于类似antd UI库的瘦身思考
我们在做react项目的时候,会用到antd之类的ui库,值得思考的一件事是,如果我们只是用到了antd中的个别组件,比如,就要把整个样式库引进来,打包就会发现,体积因为引入了整个样式大了很多。我们可以通过.babelrc实现按需引入。
瘦身前

.babelrc 增加对 antd 样式按需引入。
js 体验AI代码助手 代码解读复制代码["import", {
"libraryName":
"antd",
"libraryDirectory": "es",
"style": true
}]瘦身后

总结
如果想要优化react项目,从构建开始是必不可少的。我们要重视从构建到打包上线的每一个环节。
二 路由懒加载,路由监听器
react路由懒加载,是笔者看完dva源码中的 dynamic异步加载组件总结出来的,针对大型项目有很多页面,在配置路由的时候,如果没有对路由进行处理,一次性会加载大量路由,这对页面初始化很不友好,会延长页面初始化时间,所以我们想这用asyncRouter来按需加载页面路由。
传统路由
如果我们没有用umi等框架,需要手动配置路由的时候,也许路由会这样配置。
js 体验AI代码助手 代码解读复制代码
或者用list保存路由信息,方便在进行路由拦截,或者配置路由菜单等。
js 体验AI代码助手 代码解读复制代码const router = [
{
'path': '/index',
'component': Index
},
{
'path': '/list'',
'component': List
},
{
'path': '/detail',
'component': Detail
},
]asyncRouter懒加载路由,并实现路由监听
我们今天讲的这种react路由懒加载是基于import 函数路由懒加载, 众所周知 ,import 执行会返回一个Promise作为异步加载的手段。我们可以利用这点来实现react异步加载路由
好的一言不合上代码。。。
代码
js 体验AI代码助手 代码解读复制代码const routerObserveQueue = [] /* 存放路由卫视钩子 */
/* 懒加载路由卫士钩子 */
export const RouterHooks = {
/* 路由组件加载之前 */
beforeRouterComponentLoad: function(callback) {
routerObserveQueue.push({
type: 'before',
callback
})
},
/* 路由组件加载之后 */
afterRouterComponentDidLoaded(callback) {
routerObserveQueue.push({
type: 'after',
callback
})
}
}
/* 路由懒加载HOC */
export default function AsyncRouter(loadRouter) {
return class Content extends React.Component {
constructor(props) {
super(props)
/* 触发每个路由加载之前钩子函数 */
this.dispatchRouterQueue('before')
}
state = {Component: null}
dispatchRouterQueue(type) {
const {history} = this.props
routerObserveQueue.forEach(item => {
if (item.type === type) item.callback(history)
})
}
componentDidMount() {
if (this.state.Component) return
loadRouter()
.then(module => module.default)
.then(Component => this.setState({Component},
() => {
/* 触发每个路由加载之后钩子函数 */
this.dispatchRouterQueue('after')
}))
}
render() {
const {Component} = this.state
return Component ?: null
}
}
}asyncRouter实际就是一个高级组件,将()=>import()作为加载函数传进来,然后当外部Route加载当前组件的时候,在componentDidMount生命周期函数,加载真实的组件,并渲染组件,我们还可以写针对路由懒加载状态定制属于自己的路由监听器beforeRouterComponentLoad和afterRouterComponentDidLoaded,类似vue中 watch $route 功能。接下来我们看看如何使用。
使用
js 体验AI代码助手 代码解读复制代码import AsyncRouter ,{ RouterHooks } from './asyncRouter.js'
const { beforeRouterComponentLoad} = RouterHooks
const Index = AsyncRouter(()=>import('../src/page/home/index'))
const List = AsyncRouter(()=>import('../src/page/list'))
const Detail = AsyncRouter(()=>import('../src/page/detail'))
const index = () => {
useEffect(()=>{
/* 增加监听函数 */
beforeRouterComponentLoad((history)=>{
console.log('当前激活的路由是',history.location.pathname)
})
},[])
return}效果
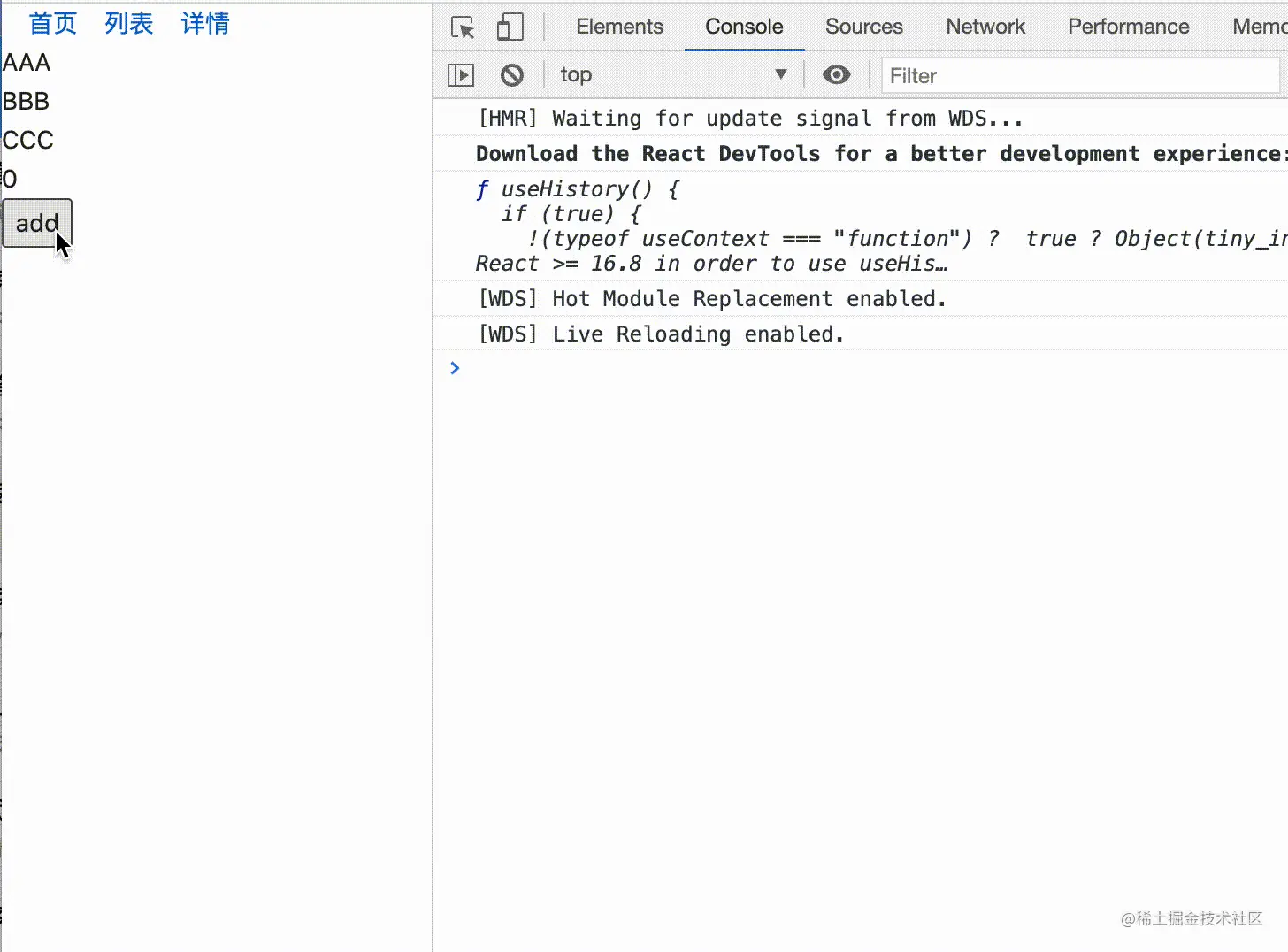
这样一来,我们既做到了路由的懒加载,又弥补了react-router没有监听当前路由变化的监听函数的缺陷。
三 受控性组件颗粒化 ,独立请求服务渲染单元
可控性组件颗粒化,独立请求服务渲染单元是笔者在实际工作总结出来的经验。目的就是避免因自身的渲染更新或是副作用带来的全局重新渲染。
1 颗粒化控制可控性组件
可控性组件和非可控性的区别就是dom元素值是否与受到react数据状态state控制。一旦由react的state控制数据状态,比如input输入框的值,就会造成这样一个场景,为了使input值实时变化,会不断setState,就会不断触发render函数,如果父组件内容简单还好,如果父组件比较复杂,会造成牵一发动全身,如果其他的子组件中componentWillReceiveProps这种带有副作用的钩子,那么引发的蝴蝶效应不敢想象。比如如下demo。
js 体验AI代码助手 代码解读复制代码class index extends React.Component{
constructor(props){
super(props)
this.state={
inputValue:''
}
}
handerChange=(e)=> this.setState({ inputValue:e.target.value })
render(){
const { inputValue } = this.state
return{ /* 我们增加三个子组件 */ }this.handerChange(e) } />{/* 我们首先来一个列表循环 */}
{
new Array(10).fill(0).map((item,index)=>{
console.log('列表循环了' )
return{item}})
}
{
/* 这里可能是更复杂的结构 */
/* ------------------ */
}}
}组件A
js 体验AI代码助手 代码解读复制代码function index(){
console.log('组件A渲染')
return我是组件A}组件B,有一个componentWillReceiveProps钩子
js 体验AI代码助手 代码解读复制代码class Index extends React.Component{
constructor(props){
super(props)
}
componentWillReceiveProps(){
console.log('componentWillReceiveProps执行')
/* 可能做一些骚操作 wu lian */
}
render(){
console.log('组件B渲染')
return我是组件B}
}组件C有一个列表循环
js 体验AI代码助手 代码解读复制代码class Index extends React.Component{
constructor(props){
super(props)
}
render(){
console.log('组件c渲染')
return我是组件c
{
new Array(10).fill(0).map((item,index)=>{
console.log('组件C列表循环了' )
return{item}})
}}
}效果
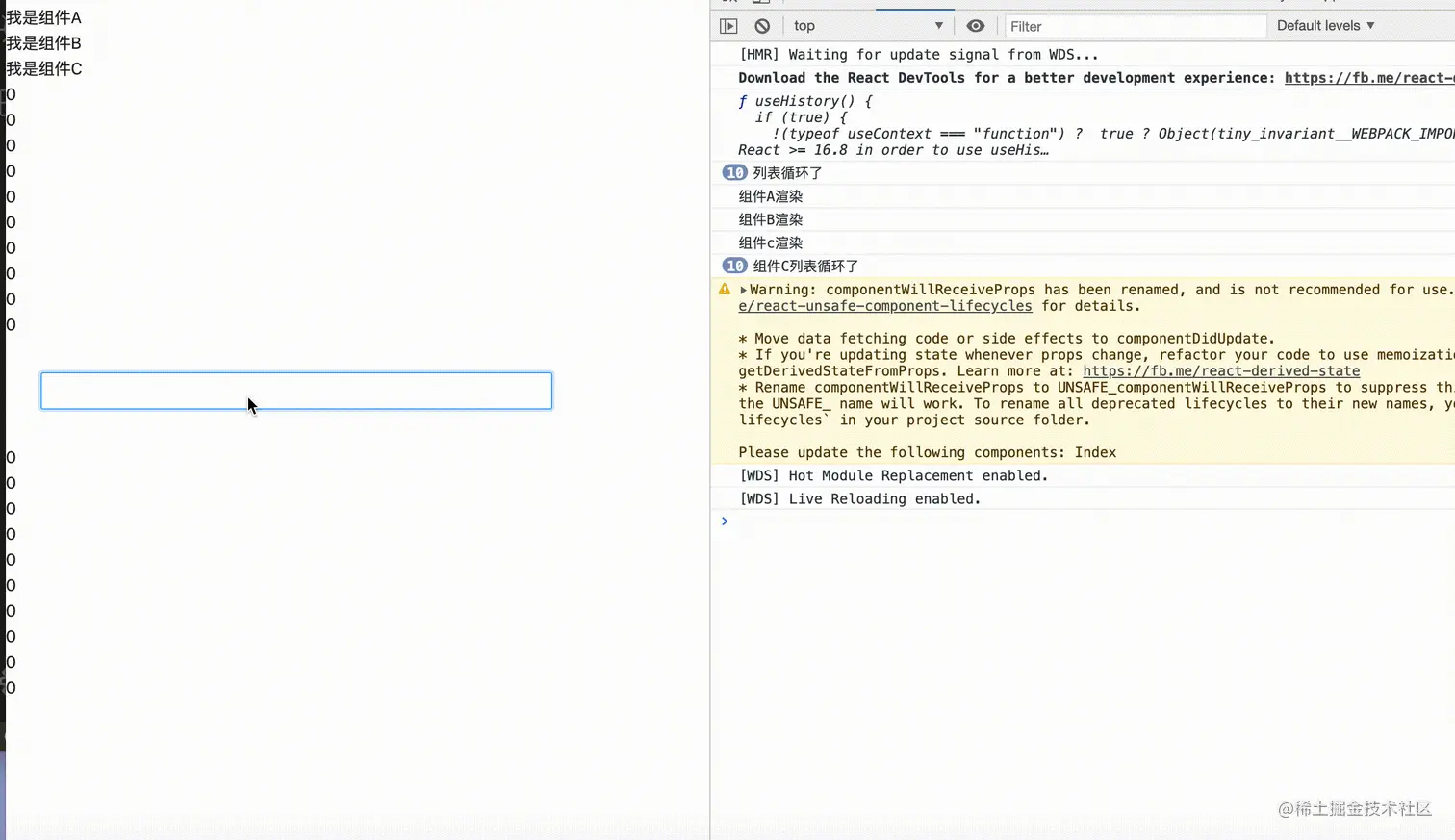
当我们在input输入内容的时候。就会造成如上的现象,所有的不该重新更新的地方,全部重新执行了一遍,这无疑是巨大的性能损耗。这个一个setState触发带来的一股巨大的由此组件到子组件可能更深的更新流,带来的副作用是不可估量的。所以我们可以思考一下,是否将这种受控性组件颗粒化,让自己更新 -> 渲染过程由自身调度。
说干就干,我们对上面的input表单单独颗粒化处理。
js 体验AI代码助手 代码解读复制代码const ComponentInput = memo(function({ notifyFatherChange }:any){
const [ inputValue , setInputValue ] = useState('')
const handerChange = useMemo(() => (e) => {
setInputValue(e.target.value)
notifyFatherChange && notifyFatherChange(e.target.value)
},[])
return})此时的组件更新由组件单元自行控制,不需要父组件的更新,所以不需要父组件设置独立state保留状态。只需要绑定到this上即可。不是所有状态都应该放在组件的 state 中. 例如缓存数据。如果需要组件响应它的变动, 或者需要渲染到视图中的数据才应该放到 state 中。这样可以避免不必要的数据变动导致组件重新渲染.
js 体验AI代码助手 代码解读复制代码class index extends React.Component{
formData :any = {}
render(){
return{ /* 我们增加三个子组件 */ }{ this.formData.inputValue = value } } />console.log(this.formData)} >打印数据{/* 我们首先来一个列表循环 */}
{
new Array(10).fill(0).map((item,index)=>{
console.log('列表循环了' )
return{item}})
}
{
/* 这里可能是更复杂的结构 */
/* ------------------ */
}}
}效果
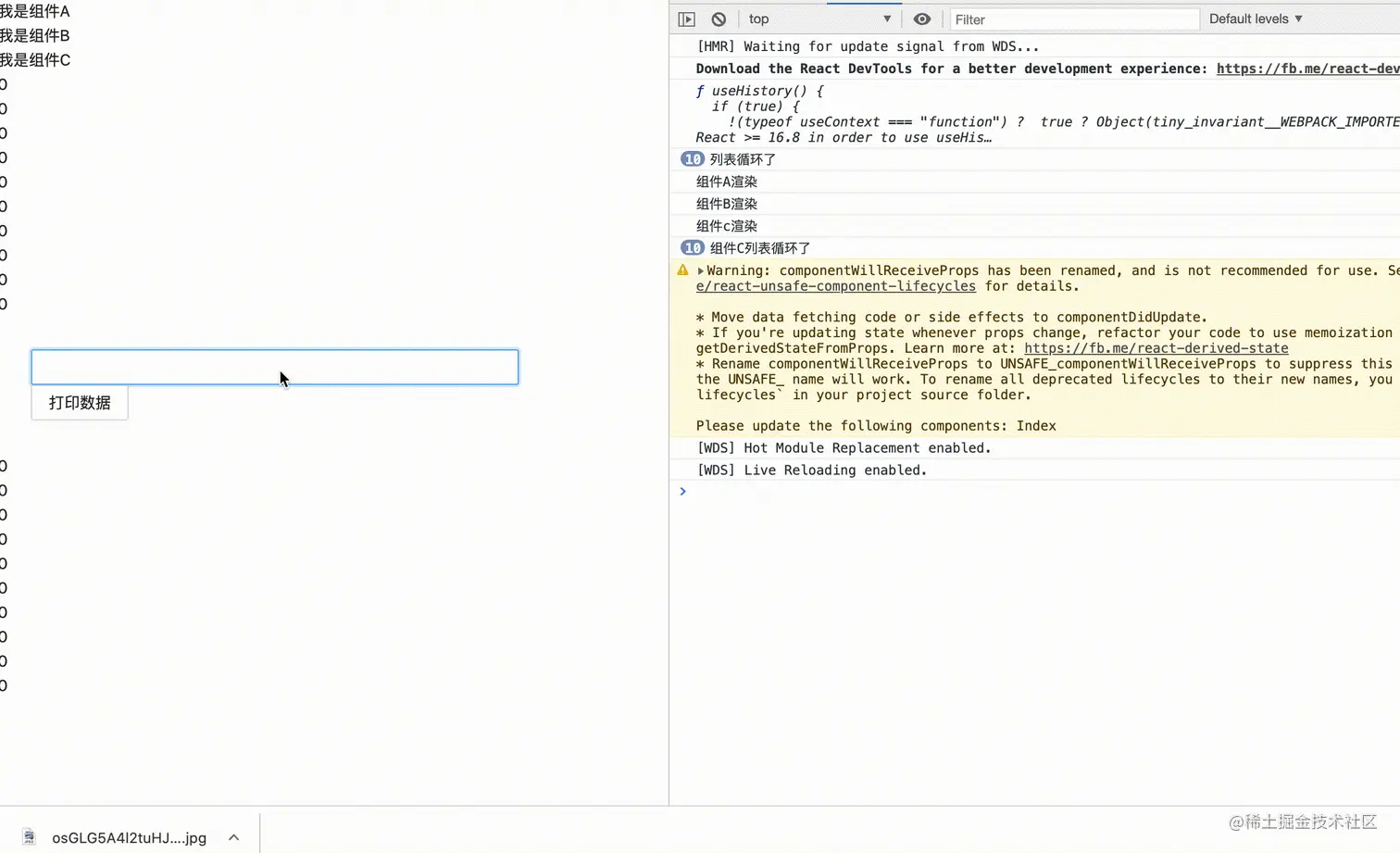
这样除了当前组件外,其他地方没有收到任何渲染波动,达到了我们想要的目的。
2 建立独立的请求渲染单元
建立独立的请求渲染单元,直接理解就是,如果我们把页面,分为请求数据展示部分(通过调用后端接口,获取数据),和基础部分(不需要请求数据,已经直接写好的),对于一些逻辑交互不是很复杂的数据展示部分,我推荐用一种独立组件,独立请求数据,独立控制渲染的模式。至于为什么我们可以慢慢分析。
首先我们看一下传统的页面模式。
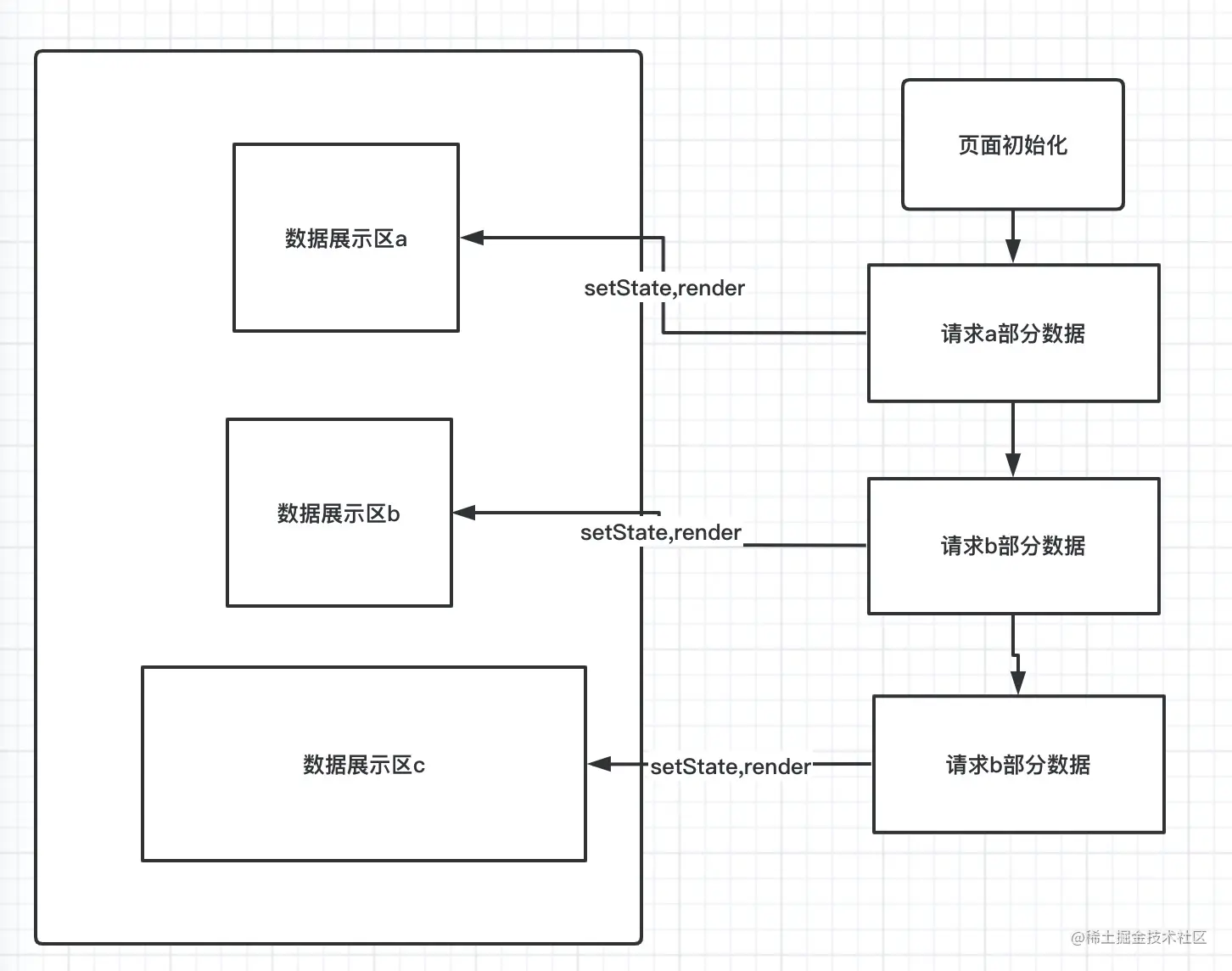
页面有三个展示区域分别,做了三次请求,触发了三次setState,渲染三次页面,即使用Promise.all等方法,但是也不保证接下来交互中,会有部分展示区重新拉取数据的可能。一旦有一个区域重新拉取数据,另外两个区域也会说、受到牵连,这种效应是不可避免的,即便react有很好的ddiff算法去调协相同的节点,但是比如长列表等情况,循环在所难免。
js 体验AI代码助手 代码解读复制代码class Index extends React.Component{
state :any={
dataA:null,
dataB:null,
dataC:null
}
async componentDidMount(){
/* 获取A区域数据 */
const dataA = await getDataA()
this.setState({ dataA })
/* 获取B区域数据 */
const dataB = await getDataB()
this.setState({ dataB })
/* 获取C区域数据 */
const dataC = await getDataC()
this.setState({ dataC })
}
render(){
const { dataA , dataB , dataC } = this.state
console.log(dataA,dataB,dataC)
return{ /* 用 dataA 数据做展示渲染 */ }{ /* 用 dataB 数据做展示渲染 */ }{ /* 用 dataC 数据做展示渲染 */ }}
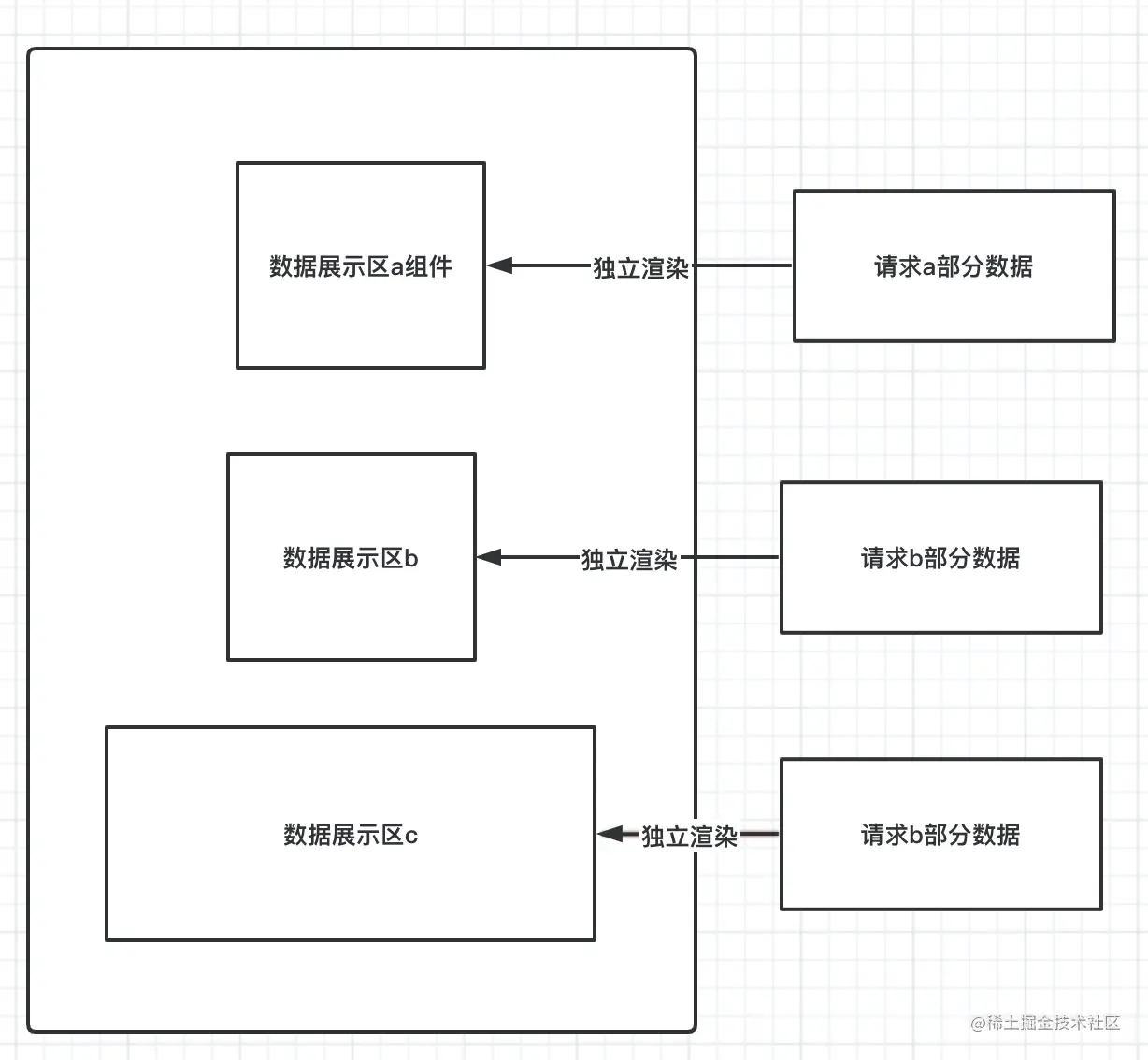
}接下来我们,把每一部分抽取出来,形成独立的渲染单元,每个组件都独立数据请求到独立渲染。
js 体验AI代码助手 代码解读复制代码function ComponentA(){
const [ dataA, setDataA ] = useState(null)
useEffect(()=>{
getDataA().then(res=> setDataA(res.data) )
},[])
return{ /* 用 dataA 数据做展示渲染 */ }}
function ComponentB(){
const [ dataB, setDataB ] = useState(null)
useEffect(()=>{
getDataB().then(res=> setDataB(res.data) )
},[])
return{ /* 用 dataB 数据做展示渲染 */ }}
function ComponentC(){
const [ dataC, setDataC ] = useState(null)
useEffect(()=>{
getDataC().then(res=> setDataC(res.data) )
},[])
return{ /* 用 dataC 数据做展示渲染 */ }}
function Index (){
return}这样一来,彼此的数据更新都不会相互影响。
总结
拆分需要单独调用后端接口的细小组件,建立独立的数据请求和渲染,这种依赖数据更新 -> 视图渲染的组件,能从整个体系中抽离出来 ,好处我总结有以下几个方面。
1 可以避免父组件的冗余渲染 ,react的数据驱动,依赖于 state 和 props 的改变,改变state 必然会对组件 render 函数调用,如果父组件中的子组件过于复杂,一个自组件的 state 改变,就会牵一发动全身,必然影响性能,所以如果把很多依赖请求的组件抽离出来,可以直接减少渲染次数。
2 可以优化组件自身性能,无论从class声明的有状态组件还是fun声明的无状态,都有一套自身优化机制,无论是用shouldupdate 还是用 hooks中 useMemouseCallback ,都可以根据自身情况,定制符合场景的渲条
件,使得依赖数据请求组件形成自己一个小的,适合自身的渲染环境。
3 能够和redux ,以及redux衍生出来 redux-action , dva,更加契合的工作,用 connect 包裹的组件,就能通过制定好的契约,根据所需求的数据更新,而更新自身,而把这种模式用在这种小的,需要数据驱动的组件上,就会起到物尽其用的效果。
四 shouldComponentUpdate ,PureComponent 和 React.memo ,immetable.js 助力性能调优
在这里我们拿immetable.js为例,讲最传统的限制更新方法,第六部分将要将一些避免重新渲染的细节。
1 PureComponent 和 React.memo
React.PureComponent 与 React.Component 用法差不多 ,但 React.PureComponent 通过props和state的浅对比来实现 shouldComponentUpate()。如果对象包含复杂的数据结构(比如对象和数组),他会浅比较,如果深层次的改变,是无法作出判断的,React.PureComponent 认为没有变化,而没有渲染试图。
如这个例子
js 体验AI代码助手 代码解读复制代码class Text extends React.PureComponent{
render(){
console.log(this.props)
returnhello,wrold}
}
class Index extends React.Component{
state={
data:{ a : 1 , b : 2 }
}
handerClick=()=>{
const { data } = this.state
data.a++
this.setState({ data })
}
render(){
const { data } = this.state
return点击}
}效果
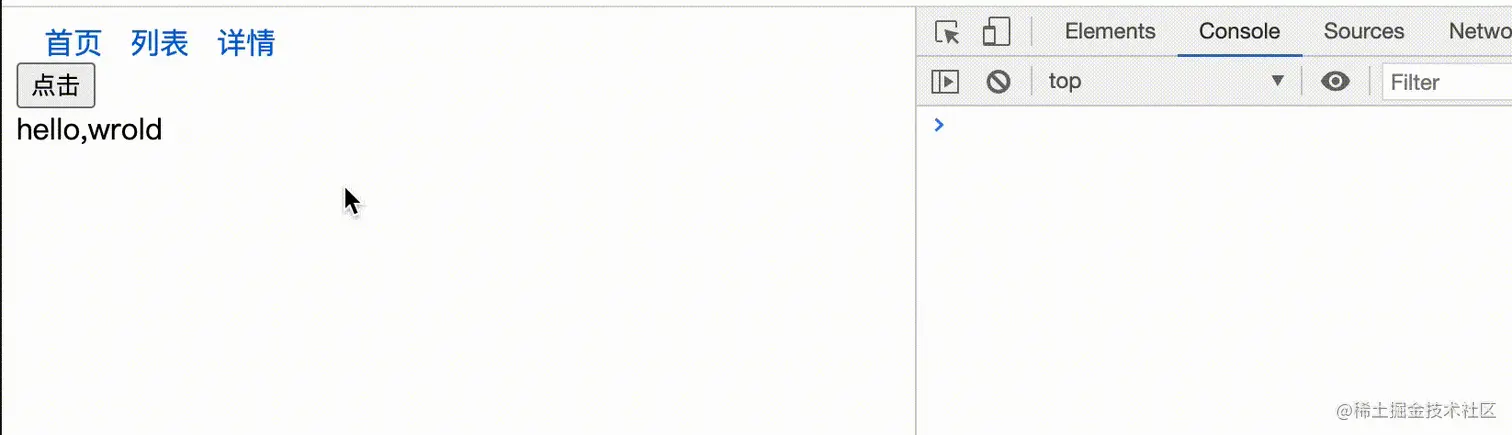
我们点击按钮,发现 data但是只是改变了data下的属性,所以 PureComponent 进行浅比较不会update。
想要解决这个问题实际也很容易。
js 体验AI代码助手 代码解读复制代码
无论组件是否是 PureComponent,如果定义了 shouldComponentUpdate(),那么会调用它并以它的执行结果来判断是否 update。在组件未定义 shouldComponentUpdate() 的情况下,会判断该组件是否是 PureComponent,如果是的话,会对新旧 props、state 进行 shallowEqual 比较,一旦新旧不一致,会触发渲染更新。
react.memo 和 PureComponent 功能类似 ,react.memo 作为第一个高阶组件,第二个参数 可以对props 进行比较 ,和shouldComponentUpdate不同的, 当第二个参数返回 true 的时候,证明props没有改变,不渲染组件,反之渲染组件。
2 shouldComponentUpdate
使用 shouldComponentUpdate() 以让React知道当state或props的改变是否影响组件的重新render,默认返回ture,返回false时不会重新渲染更新,而且该方法并不会在初始化渲染或当使用 forceUpdate() 时被调用,通常一个shouldComponentUpdate 应用是这么写的。
控制状态
js 体验AI代码助手 代码解读复制代码shouldComponentUpdate(nextProps, nextState) {
/* 当 state 中 data1 发生改变的时候,重新更新组件 */
return nextState.data1 !== this.state.data1
}这个的意思就是 仅当state 中 data1 发生改变的时候,重新更新组件。
控制prop属性
js 体验AI代码助手 代码解读复制代码shouldComponentUpdate(nextProps, nextState) {
/* 当 props 中 data2发生改变的时候,重新更新组件 */
return nextProps.data2 !== this.props.data2
}这个的意思就是 仅当props 中 data2 发生改变的时候,重新更新组件。
3 immetable.js
immetable.js 是Facebook 开发的一个js库,可以提高对象的比较性能,像之前所说的pureComponent 只能对对象进行浅比较,,对于对象的数据类型,却束手无策,所以我们可以用 immetable.js 配合 shouldComponentUpdate 或者 react.memo来使用。immutable 中
我们用react-redux来简单举一个例子,如下所示 数据都已经被 immetable.js处理。
js 体验AI代码助手 代码解读复制代码import { is } from 'immutable'
const GoodItems = connect(state =>
({ GoodItems: filter(state.getIn(['Items', 'payload', 'list']), state.getIn(['customItems', 'payload', 'list'])) || Immutable.List(), })
/* 此处省略很多代码~~~~~~ */
)(memo(({ Items, dispatch, setSeivceId }) => {
/* */
}, (pre, next) => is(pre.Items, next.Items)))通过 is 方法来判断,前后Items(对象数据类型)是否发生变化。
五 规范写法,合理处理细节问题
有的时候,我们在敲代码的时候,稍微注意以下,就能避免性能的开销。也许只是稍加改动,就能其他优化性能的效果。
①绑定事件尽量不要使用箭头函数
面临问题
众所周知,react更新来大部分情况自于props的改变(被动渲染),和state改变(主动渲染)。当我们给未加任何更新限定条件子组件绑定事件的时候,或者是PureComponent 纯组件, 如果我们箭头函数使用的话。
js 体验AI代码助手 代码解读复制代码{ console.log(666) }} />每次渲染时都会创建一个新的事件处理器,这会导致 ChildComponent 每次都会被渲染。
即便我们用箭头函数绑定给dom元素。
jsx 体验AI代码助手 代码解读复制代码{ console.log(777) } } >hello,world每次react合成事件事件的时候,也都会重新声明一个新事件。
解决问题
解决这个问题事件很简单,分为无状态组件和有状态组件。
有状态组件
js 体验AI代码助手 代码解读复制代码class index extends React.Component{
handerClick=()=>{
console.log(666)
}
handerClick1=()=>{
console.log(777)
}
render(){
returnhello,world}
}无状态组件
js 体验AI代码助手 代码解读复制代码function index(){
const handerClick1 = useMemo(()=>()=>{
console.log(777)
},[]) /* [] 存在当前 handerClick1 的依赖项*/
const handerClick = useCallback(()=>{ console.log(666) },[]) /* [] 存在当前 handerClick 的依赖项*/
returnhello,world}对于dom,如果我们需要传递参数。我们可以这么写。
js 体验AI代码助手 代码解读复制代码function index(){
const handerClick1 = useMemo(()=>(event)=>{
const mes = event.currentTarget.dataset.mes
console.log(mes) /* hello,world */
},[])
returnhello,world}②循环正确使用key
无论是react 和 vue,正确使用key,目的就是在一次循环中,找到与新节点对应的老节点,复用节点,节省开销。想深入理解的同学可以看一下笔者的另外一篇文章 全面解析 vue3.0 diff算法 里面有对key详细说明。我们今天来看以下key正确用法,和错误用法。
1 错误用法
错误用法一:用index做key
js 体验AI代码助手 代码解读复制代码function index(){
const list = [ { id:1 , name:'哈哈' } , { id:2, name:'嘿嘿' } ,{ id:3 , name:'嘻嘻' } ]
return{ list.map((item,index)=>{ item.name }) }}这种加key的性能,实际和不加key效果差不多,每次还是从头到尾diff。
错误用法二:用index拼接其他的字段
js 体验AI代码助手 代码解读复制代码function index(){
const list = [ { id:1 , name:'哈哈' } , { id:2, name:'嘿嘿' } ,{ id:3 , name:'嘻嘻' } ]
return{ list.map((item,index)=>{ item.name }) }}如果有元素移动或者删除,那么就失去了一一对应关系,剩下的节点都不能有效复用。
2 正确用法
正确用法:用唯一id作为key
js 体验AI代码助手 代码解读复制代码function index(){
const list = [ { id:1 , name:'哈哈' } , { id:2, name:'嘿嘿' } ,{ id:3 , name:'嘻嘻' } ]
return{ list.map((item,index)=>{ item.name }) }}用唯一的健id作为key,能够做到有效复用元素节点。
③无状态组件hooks-useMemo避免重复声明。
对于无状态组件,数据更新就等于函数上下文的重复执行。那么函数里面的变量,方法就会重新声明。比如如下情况。
js 体验AI代码助手 代码解读复制代码function Index(){
const [ number , setNumber ] = useState(0)
const handerClick1 = ()=>{
/* 一些操作 */
}
const handerClick2 = ()=>{
/* 一些操作 */
}
const handerClick3 = ()=>{
/* 一些操作 */
}
return点我有惊喜1 点我有惊喜2 点我有惊喜3 setNumber(number+1) } > 点击 { number }}每次点击button的时候,都会执行Index函数。handerClick1 , handerClick2,handerClick3都会重新声明。为了避免这个情况的发生,我们可以用 useMemo 做缓存,我们可以改成如下。
js 体验AI代码助手 代码解读复制代码function Index(){
const [ number , setNumber ] = useState(0)
const [ handerClick1 , handerClick2 ,handerClick3] = useMemo(()=>{
const fn1 = ()=>{
/* 一些操作 */
}
const fn2 = ()=>{
/* 一些操作 */
}
const fn3= ()=>{
/* 一些操作 */
}
return [fn1 , fn2 ,fn3]
},[]) /* 只有当数据里面的依赖项,发生改变的时候,才会重新声明函数。 */
return点我有惊喜1 点我有惊喜2 点我有惊喜3 setNumber(number+1) } > 点击 { number }}如下改变之后,handerClick1 , handerClick2,handerClick3 会被缓存下来。
④懒加载 Suspense 和 lazy
Suspense 和 lazy 可以实现 dynamic import 懒加载效果,原理和上述的路由懒加载差不多。在 React 中的使用方法是在 Suspense 组件中使用
js 体验AI代码助手 代码解读复制代码const LazyComponent = React.lazy(() => import('./LazyComponent'));
function demo () {
return (Loading...}>)
}LazyComponent 是通过懒加载加载进来的,所以渲染页面的时候可能会有延迟,但使用了 Suspense 之后,在加载状态下,可以用
Loading...作为loading效果。
Suspense 可以包裹多个懒加载组件。
js 体验AI代码助手 代码解读复制代码Loading...}>
六 多种方式避免重复渲染
避免重复渲染,是react性能优化的重要方向。如果想尽心尽力处理好react项目每一个细节,那么就要从每一行代码开始,从每一组件开始。正所谓不积硅步无以至千里。
① 学会使用的批量更新
批量更新
这次讲的批量更新的概念,实际主要是针对无状态组件和hooks中useState,和 class有状态组件中的this.setState,两种方法已经做了批量更新的处理。比如如下例子
一次更新中
js 体验AI代码助手 代码解读复制代码class index extends React.Component{
constructor(prop){
super(prop)
this.state = {
a:1,
b:2,
c:3,
}
}
handerClick=()=>{
const { a,b,c } :any = this.state
this.setState({ a:a+1 })
this.setState({ b:b+1 })
this.setState({ c:c+1 })
}
render= () =>}点击事件发生之后,会触发三次 setState,但是不会渲染三次,因为有一个批量更新batchUpdate批量更新的概念。三次setState最后被合成类似如下样子
js 体验AI代码助手 代码解读复制代码this.setState({
a:a+1 ,
b:b+1 ,
c:c+1
})无状态组件中
js 体验AI代码助手 代码解读复制代码 const [ a , setA ] = useState(1)
const [ b , setB ] = useState({})
const [ c , setC ] = useState(1)
const handerClick = () => {
setB( { ...b } )
setC( c+1 )
setA( a+1 )
}批量更新失效
当我们针对上述两种情况加以如下处理之后。
js 体验AI代码助手 代码解读复制代码handerClick=()=>{
setTimeout(() => {
this.setState({ a:a+1 })
this.setState({ b:b+1 })
this.setState({ c:c+1 })
}, 0)
}js 体验AI代码助手 代码解读复制代码 const handerClick = () => {
Promise.resolve().then(()=>{
setB( { ...b } )
setC( c+1 )
setA( a+1 )
})
}我们会发现,上述两种情况 ,组件都更新渲染了三次 ,此时的批量更新失效了。这种情况在react-hooks中也普遍存在,这种情况甚至在hooks中更加明显,因为我们都知道hooks中每个useState保存了一个状态,并不是让class声明组件中,可以通过this.state统一协调状态,再一次异步函数中,比如说一次ajax请求后,想通过多个useState改变状态,会造成多次渲染页面,为了解决这个问题,我们可以手动批量更新。
手动批量更新
react-dom 中提供了unstable_batchedUpdates方法进行手动批量更新。这个api更契合react-hooks,我们可以这样做。
js 体验AI代码助手 代码解读复制代码 const handerClick = () => {
Promise.resolve().then(()=>{
unstable_batchedUpdates(()=>{
setB( { ...b } )
setC( c+1 )
setA( a+1 )
})
})
}这样三次更新,就会合并成一次。同样达到了批量更新的效果。
② 合并state
class类组件(有状态组件)
合并state这种,是一种我们在react项目开发中要养成的习惯。我看过有些同学的代码中可能会这么写(如下demo是模拟的情况,实际要比这复杂的多)。
js 体验AI代码助手 代码解读复制代码class Index extends React.Component{
state = {
loading:false /* 用来模拟loading效果 */,
list:[],
}
componentDidMount(){
/* 模拟一个异步请求数据场景 */
this.setState({ loading : true }) /* 开启loading效果 */
Promise.resolve().then(()=>{
const list = [ { id:1 , name: 'xixi' } ,{ id:2 , name: 'haha' },{ id:3 , name: 'heihei' } ]
this.setState({ loading : false },()=>{
this.setState({
list:list.map(item=>({
...item,
name:item.name.toLocaleUpperCase()
}))
})
})
})
}
render(){
const { list } = this.state
return{
list.map(item=>{ item.name })
}}
}分别用两次this.state第一次解除loading状态,第二次格式化数据列表。这另两次更新完全没有必要,可以用一次setState更新完美解决。不这样做的原因是,对于像demo这样的简单结构还好,对于复杂的结构,一次更新可能都是宝贵的,所以我们应该学会去合并state。将上述demo这样修改。
js 体验AI代码助手 代码解读复制代码this.setState({
loading : false,
list:list.map(item=>({
...item,
name:item.name.toLocaleUpperCase()
}))
})函数组件(无状态组件)
对于无状态组件,我们可以通过一个useState保存多个状态,没有必要每一个状态都用一个useState。
对于这样的情况。
js 体验AI代码助手 代码解读复制代码const [ a ,setA ] = useState(1) const [ b ,setB ] = useState(2)
我们完全可以一个state搞定。
js 体验AI代码助手 代码解读复制代码const [ numberState , setNumberState ] = useState({ a:1 , b :2})但是要注意,如果我们的state已经成为 useEffect , useCallback , useMemo依赖项,请慎用如上方法。
③ useMemo React.memo隔离单元
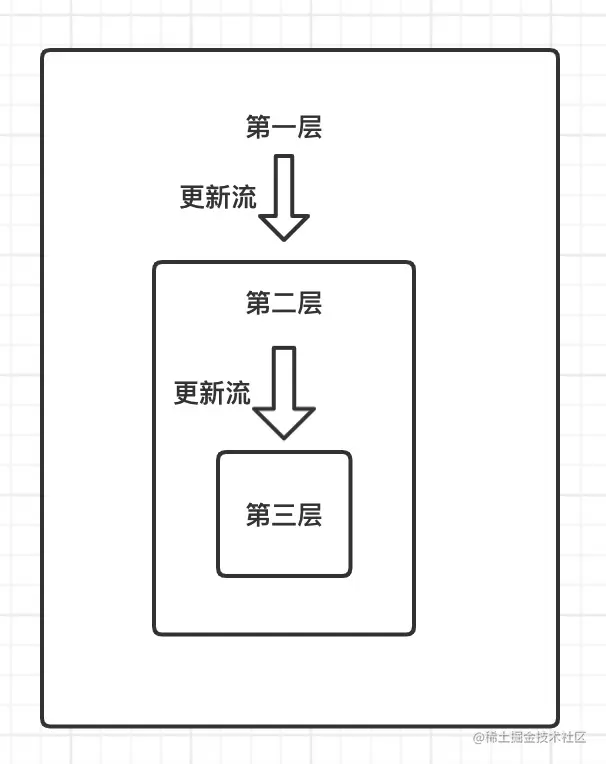
react正常的更新流,就像利剑一下,从父组件项子组件穿透,为了避免这些重复的更新渲染,shouldComponentUpdate , React.memo等api也应运而生。但是有的情况下,多余的更新在所难免,比如如下这种情况。这种更新会由父组件 -> 子组件 传递下去。
js 体验AI代码助手 代码解读复制代码function ChildrenComponent(){
console.log(2222)
returnhello,world}
function Index (){
const [ list ] = useState([ { id:1 , name: 'xixi' } ,{ id:2 , name: 'haha' },{ id:3 , name: 'heihei' } ])
const [ number , setNumber ] = useState(0)
return{ number } setNumber(number + 1) } >点击{
list.map(item=>{
console.log(1111)
return{ item.name }})
}}效果
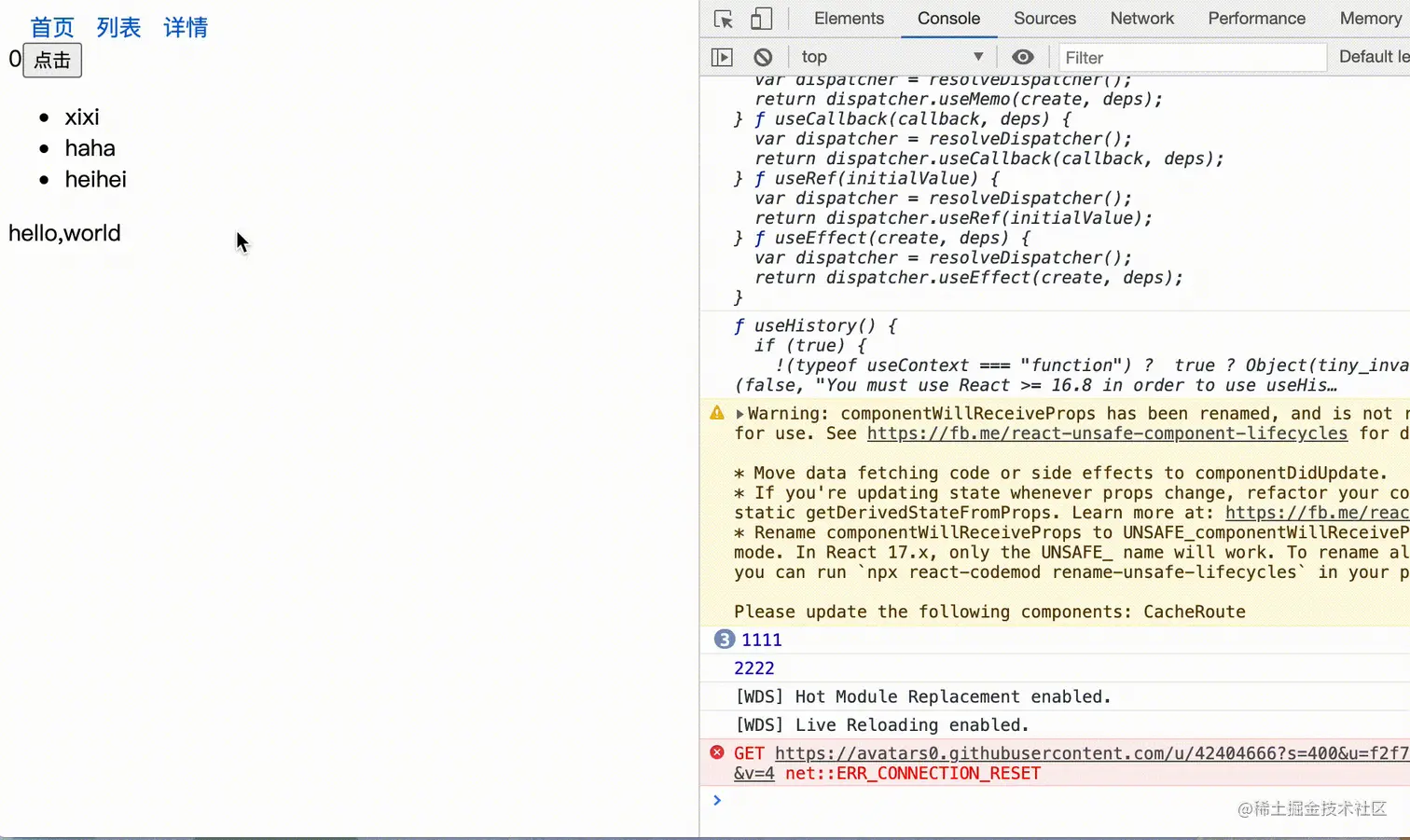
针对这一现象,我们可以通过使用useMemo进行隔离,形成独立的渲染单元,每次更新上一个状态会被缓存,循环不会再执行,子组件也不会再次被渲染,我们可以这么做。
js 体验AI代码助手 代码解读复制代码function Index (){
const [ list ] = useState([ { id:1 , name: 'xixi' } ,{ id:2 , name: 'haha' },{ id:3 , name: 'heihei' } ])
const [ number , setNumber ] = useState(0)
return{ number } setNumber(number + 1) } >点击{
useMemo(()=>(list.map(item=>{
console.log(1111)
return{ item.name }})),[ list ])
}{ useMemo(()=>,[]) }}有状态组件
在class声明的组件中,没有像 useMemo 的API ,但是也并不等于束手无策,我们可以通过 react.memo 来阻拦来自组件本身的更新。我们可以写一个组件,来控制react 组件更新的方向。我们通过一个
js 体验AI代码助手 代码解读复制代码/* 控制更新 ,第二个参数可以作为组件更新的依赖 , 这里设置为 ()=> true 只渲染一次 */
const NotUpdate = React.memo(({ children }:any)=> typeof children === 'function' ? children() : children ,()=>true)
class Index extends React.Component{
constructor(prop){
super(prop)
this.state = {
list: [ { id:1 , name: 'xixi' } ,{ id:2 , name: 'haha' },{ id:3 , name: 'heihei' } ],
number:0,
}
}
handerClick = ()=>{
this.setState({ number:this.state.number + 1 })
}
render(){
const { list }:any = this.state
return点击{()=>({
list.map(item=>{
console.log(1111)
return{ item.name }})
})}}
}js 体验AI代码助手 代码解读复制代码const NotUpdate = React.memo(({ children }:any)=> typeof children === 'function' ? children() : children ,()=>true)
没错,用的就是 React.memo,生成了阻断更新的隔离单元,如果我们想要控制更新,可以对 React.memo 第二个参数入手, demo项目中完全阻断的更新。
④ ‘取缔’state,学会使用缓存。
这里的取缔state,并完全不使用state来管理数据,而是善于使用state,知道什么时候使用,怎么使用。react 并不像 vue 那样响应式数据流。 在 vue中 有专门的dep做依赖收集,可以自动收集字符串模版的依赖项,只要没有引用的data数据, 通过 this.aaa = bbb ,在vue中是不会更新渲染的。因为 aaa 的dep没有收集渲染watcher依赖项。在react中,我们触发this.setState 或者 useState,只会关心两次state值是否相同,来触发渲染,根本不会在乎jsx语法中是否真正的引入了正确的值。
没有更新作用的state
有状态组件中
js 体验AI代码助手 代码解读复制代码class Demo extends React.Component{
state={ text:111 }
componentDidMount(){
const { a } = this.props
/* 我们只是希望在初始化,用text记录 props中 a 的值 */
this.setState({
text:a
})
}
render(){
/* 没有引入text */
return{'hello,world'}}
}如上例子中,render函数中并没有引入text ,我们只是希望在初始化的时候,用 text 记录 props 中 a 的值。我们却用 setState 触发了一次无用的更新。无状态组件中情况也一样存在,具体如下。
无状态组件中
js 体验AI代码助手 代码解读复制代码function Demo ({ a }){
const [text , setText] = useState(111)
useEffect(()=>{
setText(a)
},[])
return{'hello,world'}}改为缓存
有状态组件中
在class声明组件中,我们可以直接把数据绑定给this上,来作为数据缓存。
js 体验AI代码助手 代码解读复制代码class Demo extends React.Component{
text = 111
componentDidMount(){
const { a } = this.props
/* 数据直接保存在text上 */
this.text = a
}
render(){
/* 没有引入text */
return{'hello,world'}}
}无状态组件中
在无状态组件中, 我们不能往问this,但是我们可以用useRef来解决问题。
js 体验AI代码助手 代码解读复制代码function Demo ({ a }){
const text = useRef(111)
useEffect(()=>{
text.current = a
},[])
return{'hello,world'}}⑤ useCallback回调
useCallback 的真正目的还是在于缓存了每次渲染时 inline callback 的实例,这样方便配合上子组件的 shouldComponentUpdate 或者 React.memo 起到减少不必要的渲染的作用。对子组件的渲染限定来源与,对子组件props比较,但是如果对父组件的callback做比较,无状态组件每次渲染执行,都会形成新的callback ,是无法比较,所以需要对callback做一个 memoize 记忆功能,我们可以理解为useCallback就是 callback加了一个memoize。我们接着往下看👇👇👇。
js 体验AI代码助手 代码解读复制代码function demo (){
const [ number , setNumber ] = useState(0)
return{ setNumber(number+1) } } />}或着
js 体验AI代码助手 代码解读复制代码function demo (){
const [ number , setNumber ] = useState(0)
const handerChange = ()=>{
setNumber(number+1)
}
return}无论是上述那种方式,pureComponent 和 react.memo 通过浅比较方式,只能判断每次更新都是新的callback,然后触发渲染更新。useCallback给加了一个记忆功能,告诉我们子组件,两次是相同的 callback无需重新更新页面。至于什么时候callback更改,就要取决于 useCallback 第二个参数。好的,将上述demo我们用 useCallback 重写。
js 体验AI代码助手 代码解读复制代码function demo (){
const [ number , setNumber ] = useState(0)
const handerChange = useCallback( ()=>{
setNumber(number+1)
},[])
return}这样 pureComponent 和 react.memo 可以直接判断是callback没有改变,防止了不必要渲染。
七 中规中矩的使用状态管理
无论我们使用的是redux还是说 redux 衍生出来的 dva ,redux-saga等,或者是mobx,都要遵循一定'使用规则',首先让我想到的是,什么时候用状态管理,怎么合理的应用状态管理,接下来我们来分析一下。
什么时候使用状态管理
要问我什么时候适合使用状态状态管理。我一定会这么分析,首先状态管理是为了解决什么问题,状态管理能够解决的问题主要分为两个方面,一 就是解决跨层级组件通信问题 。二 就是对一些全局公共状态的缓存。
我们那redux系列的状态管理为例子。
我见过又同学这么写的
滥用状态管理
tsx 体验AI代码助手 代码解读复制代码/* 和 store下面text模块的list列表,建立起依赖关系,list更新,组件重新渲染 */
@connect((store)=>({ list:store.text.list }))
class Text extends React.Component{
constructor(prop){
super(prop)
}
componentDidMount(){
/* 初始化请求数据 */
this.getList()
}
getList=()=>{
const { dispatch } = this.props
/* 获取数据 */
dispatch({ type:'text/getDataList' })
}
render(){
const { list } = this.props
return{
list.map(item=>{ /* 做一些渲染页面的操作.... */ })
}this.getList() } >重新获取列表}
}这样页面请求数据,到数据更新,全部在当前组件发生,这个写法我不推荐,此时的数据走了一遍状态管理,最终还是回到了组件本身,显得很鸡肋,并没有发挥什么作用。在性能优化上到不如直接在组件内部请求数据。
不会合理使用状态管理
还有的同学可能这么写。
js 体验AI代码助手 代码解读复制代码class Text extends React.Component{
constructor(prop){
super(prop)
this.state={
list:[],
}
}
async componentDidMount(){
const { data , code } = await getList()
if(code === 200){
/* 获取的数据有可能是不常变的,多个页面需要的数据 */
this.setState({
list:data
})
}
}
render(){
const { list } = this.state
return{ /* 下拉框 */ }{
list.map(item=>{ item.name })
}}
}对于不变的数据,多个页面或组件需要的数据,为了避免重复请求,我们可以将数据放在状态管理里面。
如何使用状态管理
分析结构
我们要学会分析页面,那些数据是不变的,那些是随时变动的,用以下demo页面为例子:

如上 红色区域,是基本不变的数据,多个页面可能需要的数据,我们可以统一放在状态管理中,蓝色区域是随时更新的数据,直接请求接口就好。
总结
不变的数据,多个页面可能需要的数据,放在状态管理中,对于时常变化的数据,我们可以直接请求接口
八 海量数据优化-时间分片,虚拟列表
时间分片
时间分片的概念,就是一次性渲染大量数据,初始化的时候会出现卡顿等现象。我们必须要明白的一个道理,js执行永远要比dom渲染快的多。 ,所以对于大量的数据,一次性渲染,容易造成卡顿,卡死的情况。我们先来看一下例子
js 体验AI代码助手 代码解读复制代码class Index extends React.Component{
state={
list: []
}
handerClick=()=>{
let starTime = new Date().getTime()
this.setState({
list: new Array(40000).fill(0)
},()=>{
const end = new Date().getTime()
console.log( (end - starTime ) / 1000 + '秒')
})
}
render(){
const { list } = this.state
console.log(list)
return点击{
list.map((item,index)=>{ item + '' + index } Item)
}}
}我们模拟一次性渲染 40000 个数据的列表,看一下需要多长时间。
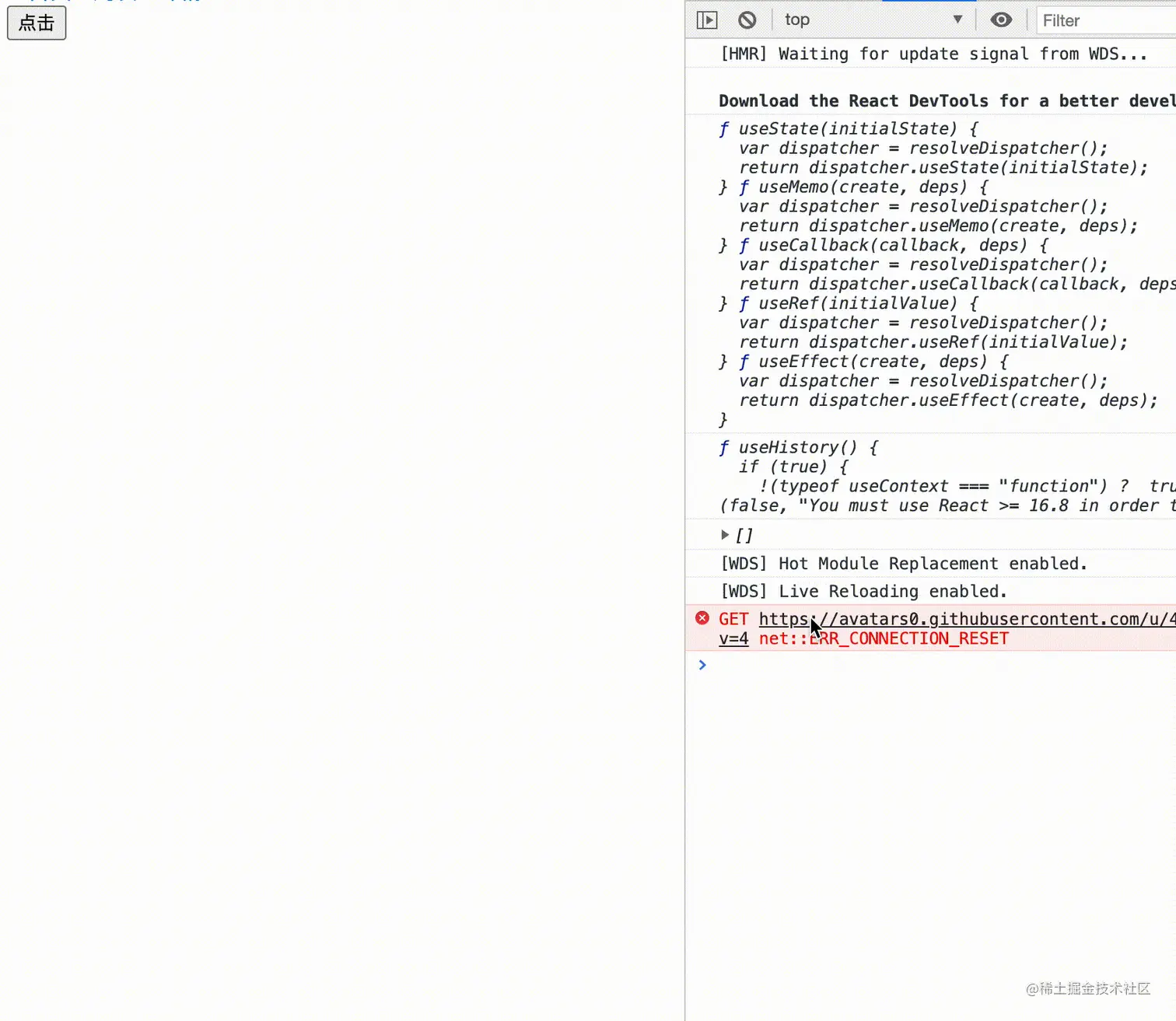
我们看到 40000 个 简单列表渲染了,将近5秒的时间。为了解决一次性加载大量数据的问题。我们引出了时间分片的概念,就是用setTimeout把任务分割,分成若干次来渲染。一共40000个数据,我们可以每次渲染100个, 分次400渲染。
js 体验AI代码助手 代码解读复制代码class Index extends React.Component{
state={
list: []
}
handerClick=()=>{
this.sliceTime(new Array(40000).fill(0), 0)
}
sliceTime=(list,times)=>{
if(times === 400) return
setTimeout(() => {
const newList = list.slice( times , (times + 1) * 100 ) /* 每次截取 100 个 */
this.setState({
list: this.state.list.concat(newList)
})
this.sliceTime( list ,times + 1 )
}, 0)
}
render(){
const { list } = this.state
return点击{
list.map((item,index)=>{ item + '' + index } Item)
}}
}效果
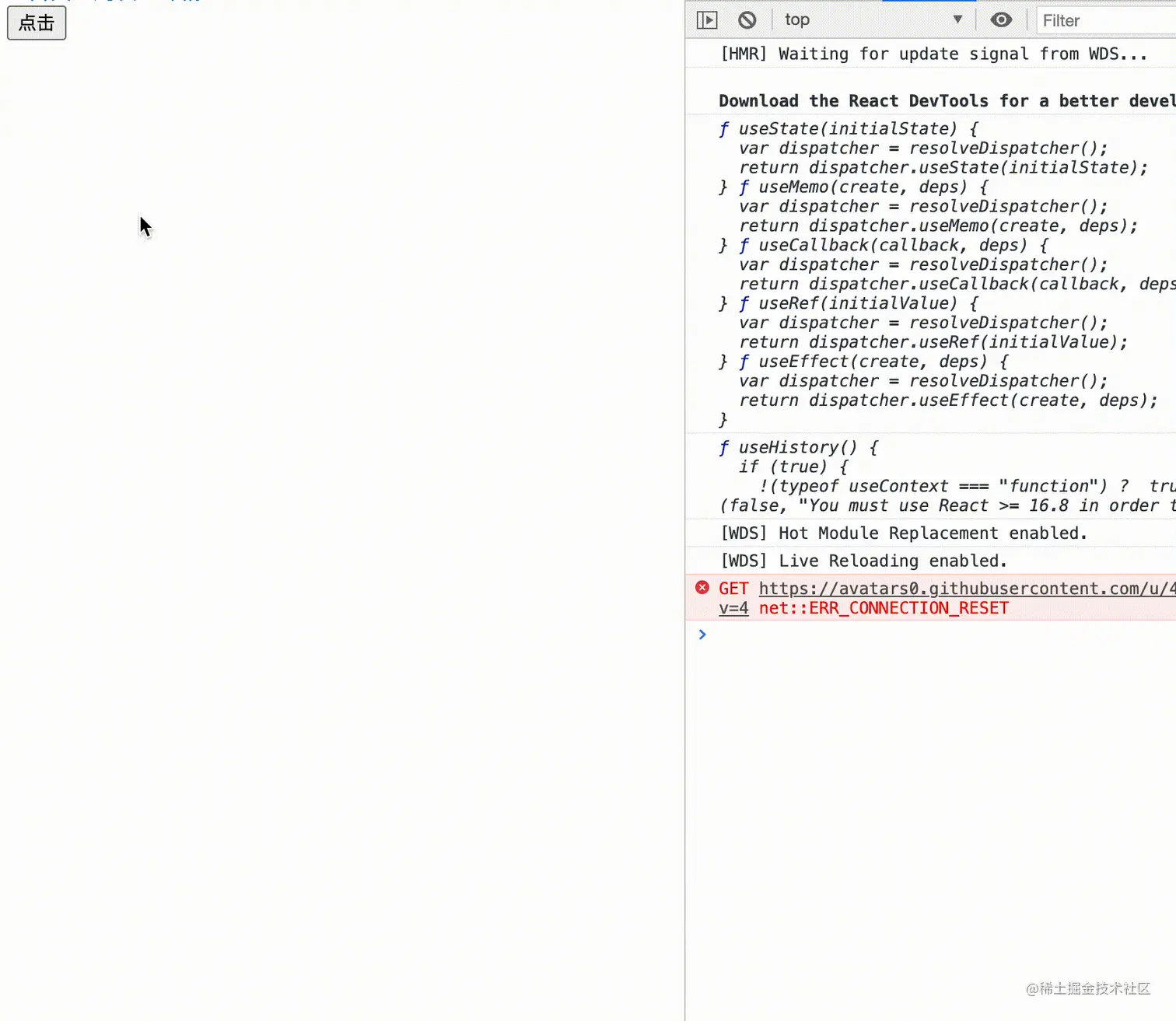
setTimeout 可以用 window.requestAnimationFrame() 代替,会有更好的渲染效果。
我们demo使用列表做的,实际对于列表来说,最佳方案是虚拟列表,而时间分片,更适合热力图,地图点位比较多的情况。
虚拟列表
笔者在最近在做小程序商城项目,有长列表的情况, 可是肯定说 虚拟列表 是解决长列表渲染的最佳方案。无论是小程序,或者是h5 ,随着 dom元素越来越多,页面会越来越卡顿,这种情况在小程序更加明显 。稍后,笔者讲专门写一篇小程序长列表渲染缓存方案的文章,感兴趣的同学可以关注一下笔者。
虚拟列表是按需显示的一种技术,可以根据用户的滚动,不必渲染所有列表项,而只是渲染可视区域内的一部分列表元素的技术。正常的虚拟列表分为 渲染区,缓冲区 ,虚拟列表区。
如下图所示。
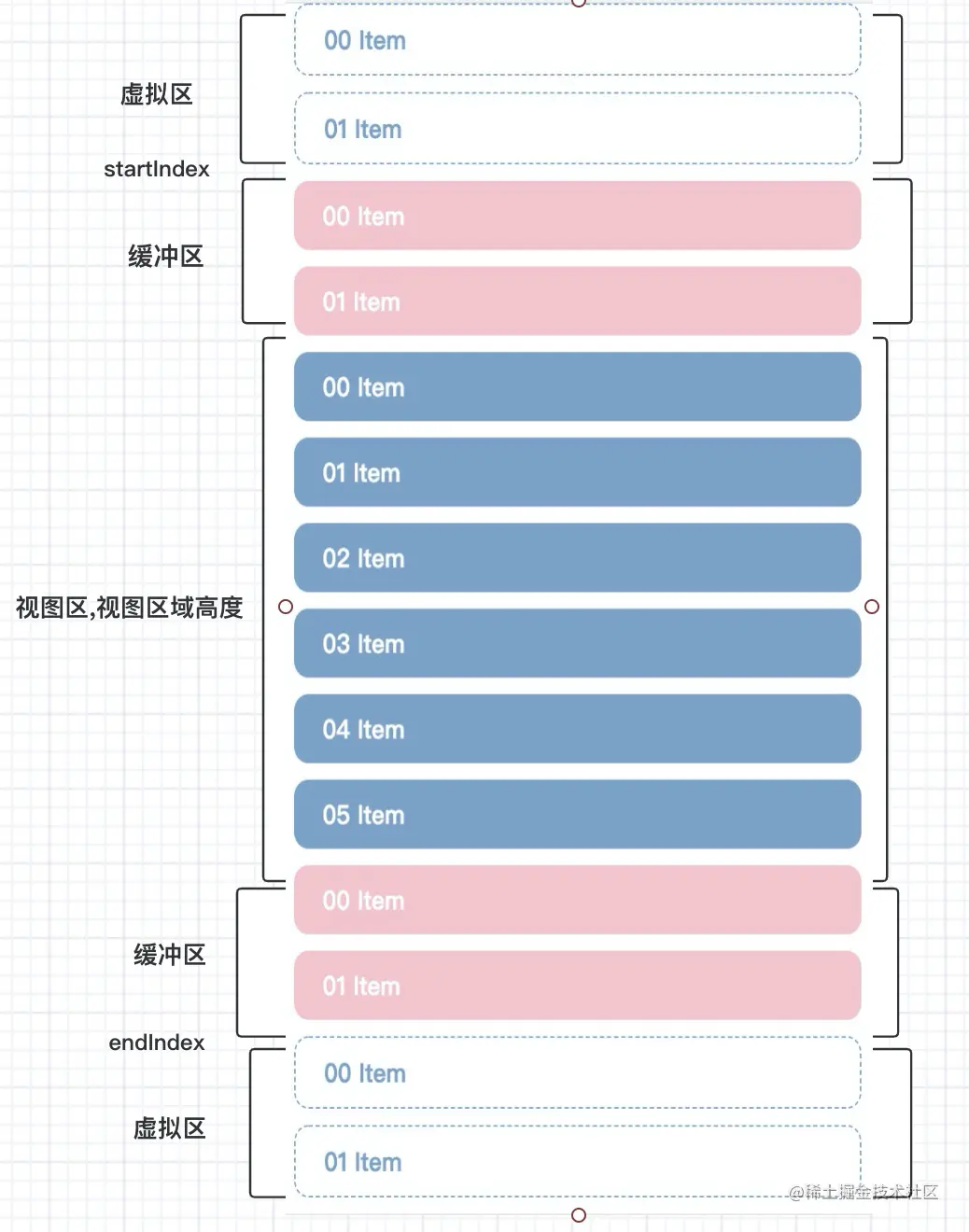
为了防止大量dom存在影响性能,我们只对,渲染区和缓冲区的数据做渲染,,虚拟列表区 没有真实的dom存在。 缓冲区的作用就是防止快速下滑或者上滑过程中,会有空白的现象。
react-tiny-virtual-list
react-tiny-virtual-list 是一个较为轻量的实现虚拟列表的组件。这是官方文档。
js 体验AI代码助手 代码解读复制代码import React from 'react';
import {render} from 'react-dom';
import VirtualList from 'react-tiny-virtual-list';
const data = ['A', 'B', 'C', 'D', 'E', 'F', ...];
render(// The style property contains the item's absolute position
Letter: {data[index]}, Row: #{index}}
/>,
document.getElementById('root')
);手写一个react虚拟列表
js 体验AI代码助手 代码解读复制代码let num = 0
class Index extends React.Component{
state = {
list: new Array(9999).fill(0).map(() =>{
num++
return num
}),
scorllBoxHeight: 500, /* 容器高度(初始化高度) */
renderList: [], /* 渲染列表 */
itemHeight: 60, /* 每一个列表高度 */
bufferCount: 8, /* 缓冲个数 上下四个 */
renderCount: 0, /* 渲染数量 */
start: 0, /* 起始索引 */
end: 0 /* 终止索引 */
}
listBox: any = null
scrollBox : any = null
scrollContent:any = null
componentDidMount() {
const { itemHeight, bufferCount } = this.state
/* 计算容器高度 */
const scorllBoxHeight = this.listBox.offsetHeight
const renderCount = Math.ceil(scorllBoxHeight / itemHeight) + bufferCount
const end = renderCount + 1
this.setState({
scorllBoxHeight,
end,
renderCount,
})
}
/* 处理滚动效果 */
handerScroll=()=>{
const { scrollTop } :any = this.scrollBox
const { itemHeight , renderCount } = this.state
const currentOffset = scrollTop - (scrollTop % itemHeight)
/* translate3d 开启css cpu 加速 */
this.scrollContent.style.transform = `translate3d(0, ${currentOffset}px, 0)`
const start = Math.floor(scrollTop / itemHeight)
const end = Math.floor(scrollTop / itemHeight + renderCount + 1)
this.setState({
start,
end,
})
}
/* 性能优化:只有在列表start 和 end 改变的时候在渲染列表 */
shouldComponentUpdate(_nextProps, _nextState){
const { start , end } = _nextState
return start !== this.state.start || end !==this.state.end
}
/* 处理滚动效果 */
render() {
console.log(1111)
const { list, scorllBoxHeight, itemHeight ,start ,end } = this.state
const renderList = list.slice(start,end)
returnthis.listBox = node}
>this.scrollBox = node }
onScroll={ this.handerScroll }
>
{ /* 占位作用 */}{ /* 显然区 */ }this.scrollContent = node} style={{ position: 'relative', left: 0, top: 0, right: 0 }} >
{
renderList.map((item, index) => ({item + '' } Item))
}}
}效果
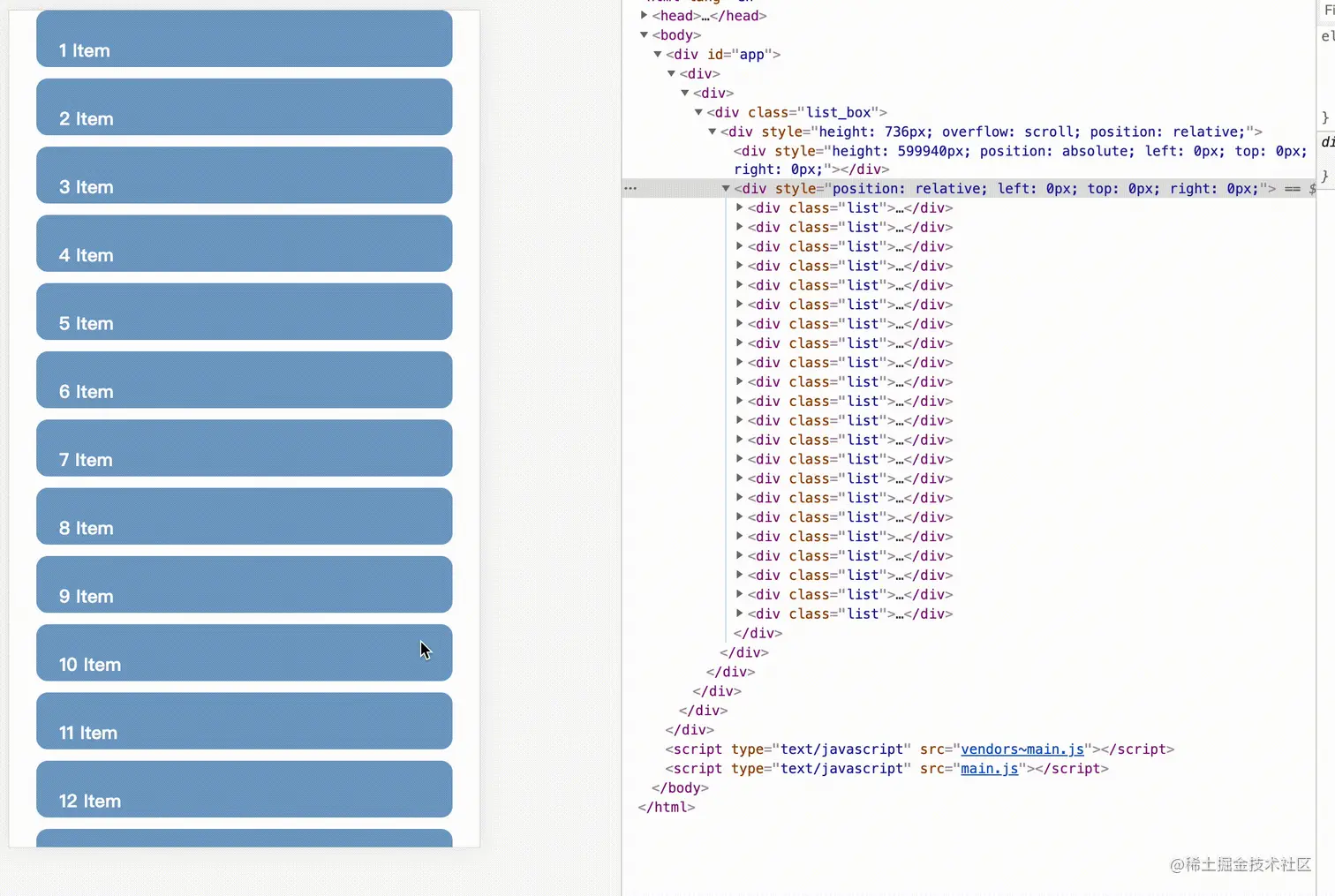
具体思路
① 初始化计算容器的高度。截取初始化列表长度。这里我们需要div占位,撑起滚动条。
② 通过监听滚动容器的 onScroll事件,根据 scrollTop 来计算渲染区域向上偏移量, 我们要注意的是,当我们向下滑动的时候,为了渲染区域,能在可视区域内,可视区域要向上的滚动; 我们向上滑动的时候,可视区域要向下的滚动。
③ 通过重新计算的 end 和 start 来重新渲染列表。
性能优化点
① 对于移动视图区域,我们可以用 transform 来代替改变 top值。
② 虚拟列表实际情况,是有 start 或者 end 改变的时候,在重新渲染列表,所以我们可以用之前 shouldComponentUpdate 来调优,避免重复渲染。
总结
react 性能优化是一个攻坚战,需要付出很多努力,将我们的项目做的更完美,希望看完这片文章的朋友们能找到react优化的方向,让我们的react项目飞起来。
下一篇
CSS 奇思妙想边框动画
相关文章

广告赞助


热门文章
-
⛳前端进阶:SEO 全方位解决方案
2023-06-07 -
Claude Code完全指南:2025年最强AI编程助手深度评测
2025-06-06 -

提升前端SEO的技巧与方法
2024-08-04 -
别再吹通用型Al Agent了!其实真实业务都是Workflow
2025-04-28 -
Trae Pro 付费版来啦!🤔 你会掏钱吗?
2025-03-15 -
OCR识别常见的八大开源工具
2023-07-31 -

Vue 3.4 发布
2023-12-29 -
AI - 发现一个超级好用的 AI 聚合平台
2024-06-10
有话要说...