😧纳尼?前端也能做这么复杂的事情了?

前言
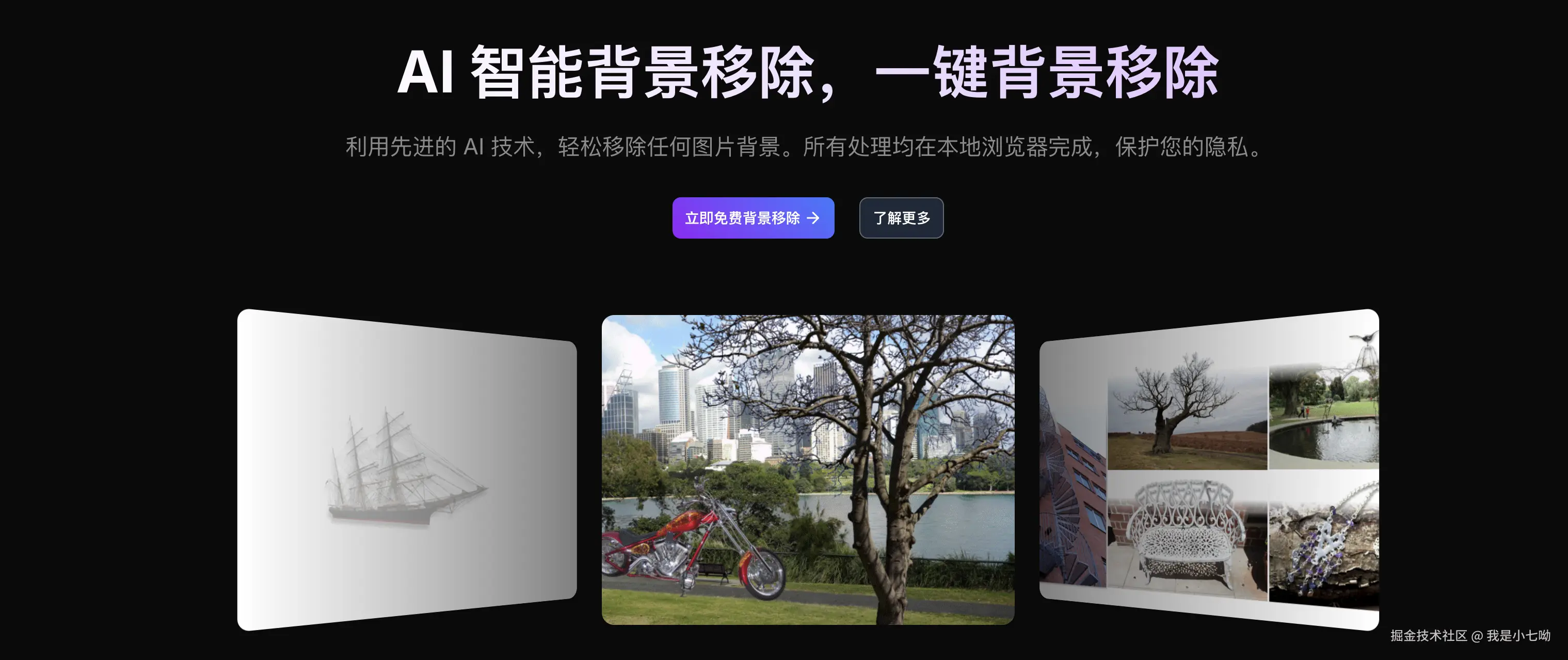
我偶然间发现一个宝藏网站,aicut.online 是一款基于本地AI实现的背景移除工具。
我研究了一下,发现他是使用了u2net模型 + onnxruntime-web实现的本地模型推理能力,下面简单介绍一下这些概念。
github:github.com/yuedud/aicu… 体验网址:aicut.online
概念
WebAssembly
基本概念: WebAssembly 是一种低级的二进制指令格式,设计目标是成为一种高效、可移植、安全的编译目标,使其能在现代 Web 浏览器中运行。你可以把它想象成一种为 Web 设计的“通用机器语言”。
核心特点:
高性能: 它不是解释执行的(像传统 JavaScript),而是被设计成可以以接近原生代码的速度运行。它提供线性内存模型和低级操作,便于编译器优化。可移植性: Wasm 模块是平台无关的,可以在支持 Wasm 的任何浏览器(或运行时环境)中运行,无需修改。安全性: 它在内存安全的沙箱环境中执行,无法直接访问主机操作系统或 DOM。只能通过明确定义的 API 与宿主环境(如浏览器)交互。多语言支持: 开发者可以使用 C、C++、Rust、Go 等多种语言编写代码,然后编译成 Wasm 模块,在浏览器中运行。这使得重用现有的高性能库或编写对性能要求极高的新功能成为可能。
目标: 解决 JavaScript 在处理计算密集型任务(如游戏物理引擎、视频编辑、3D渲染、科学计算、加密解密、机器学习模型推理等)时性能不足的问题,同时保持 Web 的安全性和可移植性。
简单比喻: 就像为浏览器引入了一个新的、更接近硬件的“CPU 指令集”,让浏览器能直接运行编译好的高性能代码。
Onnxruntime-Web
基本概念: onnxruntime-web 是 ONNX Runtime 的一个专门构建的版本,目的是让开发者能够直接在 Web 浏览器中运行 ONNX 格式的机器学习模型。
核心特点:
ONNX 支持: 它理解并执行符合 ONNX 标准的模型文件。ONNX 是一个开放的模型格式,允许模型在各种框架之间转换和互操作。
浏览器内推理: 最大的价值在于它允许 ML 模型的推理计算完全在用户的浏览器中发生,无需依赖远程服务器。这带来了低延迟、隐私保护(数据无需离开用户设备)和离线能力。
多种后端执行引擎: 为了适应不同的浏览器环境、设备性能和模型需求,它提供了多种执行引擎后端:
WebAssembly (Wasm): 提供接近原生的性能,是主要的跨浏览器高性能后端。支持单线程和多线程(需浏览器支持)。WebGL: 利用 GPU 进行加速,尤其适合某些计算模式与图形处理相似的模型(如卷积神经网络)。性能潜力高,但兼容性和精度可能不如 Wasm。WebNN (预览/实验性): 旨在利用操作系统提供的原生 ML 硬件加速(如 NPU)。性能潜力最高,但目前浏览器支持有限。JavaScript (CPU): 兼容性最好但速度最慢的后备方案。
优化: 包含针对 Web 环境(特别是 Wasm 和 WebGL)的特定优化,以提升模型在浏览器中的运行效率。
目标: 降低在 Web 应用中集成和部署机器学习模型的门槛,提供高性能、跨平台的浏览器内推理能力。
简单比喻: 它是一个专门为浏览器定制的“机器学习模型运行引擎”,支持多种“驱动方式”(Wasm, WebGL, WebNN),让各种 ONNX 格式的模型能在网页里“活”起来并高效工作。
u2net
基本概念: u2net 是一种深度学习神经网络架构,特别设计用于显著目标检测任务。它的核心任务是从图像或视频中精确地分割出最吸引人注意的前景目标。
核心特点:
嵌套 U 型结构: 这是其名称的由来(U^2-Net)。它包含一个主 U 型编码器-解码器网络,并且在每个阶段内部又嵌套了更小的 U 型块(ReSidual U-blocks, RSU)。这种设计能更有效地捕捉不同尺度的上下文信息,同时保持高分辨率的细节。
多尺度特征融合: 通过嵌套的 RSU 块和跳跃连接,模型能融合来自不同深度和尺度的特征,这对精确描绘目标边界至关重要。
高效性: 相比一些非常深的网络(如 ResNet),u2net 结构相对轻量,但性能优异。
应用广泛: 主要用于高质量的图像/视频前景背景分割(抠图)。典型的应用包括:
移除或替换图片/视频背景创建透明 PNG 图像人像分割视频会议虚拟背景图像编辑工具
目标: 提供一种高效且准确的架构,解决图像中前景目标的精确分割问题。
简单比喻: u2net 是一个专门训练出来的“智能剪刀手”,它能自动识别图片里最重要的主体(比如人、动物、物体),并用极高的精度把它从背景中“剪”出来。
技术架构
架构图
+-------------------------------------------------------+ | **用户层 (Web Application)** | +-------------------------------------------------------+ | - 用户界面 (HTML, CSS) | | - 业务逻辑 (JavaScript/TypeScript) | | * 捕获用户输入 (e.g., 上传图片/视频流) | | * 调用 `onnxruntime-web` API 执行推理 | | * 处理输出 (e.g., 显示抠图结果,合成新背景) | +-------------------------------------------------------+ ↓ (JavaScript API 调用) +-------------------------------------------------------+ | **模型服务层 (ONNX Runtime Web)** | +-------------------------------------------------------+ | - **onnxruntime-web** 库 (JavaScript) | | * 加载并解析 **u2net.onnx** 模型文件 | | * 管理输入/输出张量 (Tensor) 的内存 | | * 调度计算任务到下层执行引擎 | | * 提供统一的 JavaScript API 给上层应用 | +-------------------------------------------------------+ ↓ (选择最佳后端执行) +-------------------------------------------------------+ | **执行引擎层 (Runtime Backends)** | +-------------------------------------------------------+ | +---------------------+ +---------------------+ | | | **WebAssembly (Wasm)** | **WebGL** | ... | | +---------------------+ +---------------------+ | | | * **核心加速引擎** | * 利用GPU加速 | | | | * 接近原生CPU速度 | * 适合特定计算模式 | | | | * 安全沙箱环境 | * 兼容性/精度限制 | | | | * 多线程支持 (可选) | | | | +---------------------+ +---------------------+ | | **首选后端** **备选/补充后端** | +-------------------------------------------------------+ ↓ (执行编译后的低级代码) +-------------------------------------------------------+ | **模型层 (U2Net 神经网络)** | +-------------------------------------------------------+ | - **u2net.onnx** 模型文件 | | * 包含训练好的 u2net 网络架构 (嵌套U型结构) | | * 包含网络权重参数 | | * 格式:开放神经网络交换格式 (ONNX) | | * 任务:显著目标检测 / 图像抠图 | +-------------------------------------------------------+ ↓ (模型文件来源) +-------------------------------------------------------+ | **资源层 (Browser Environment)** | +-------------------------------------------------------+ | - 模型文件存储: HTTP Server / IndexedDB / Cache API | | - 浏览器提供: WebAssembly 引擎, WebGL API, WebNN API | | - 计算资源: CPU (Wasm), GPU (WebGL), NPU (WebNN) | +-------------------------------------------------------+
详细解释
用户层 (Web Application):
这是用户直接交互的网页界面。使用 JavaScript/TypeScript 编写应用逻辑。核心操作:获取用户输入(如图片或视频帧),调用 onnxruntime-web 提供的 API 来运行 u2net 模型进行抠图推理,接收模型输出的结果(通常是掩码图或透明度通道),最后将结果渲染给用户(如显示抠好的图或与背景合成)。
模型服务层 (ONNX Runtime Web):
核心枢纽。这是集成到 Web 应用中的 JavaScript 库。负责加载存储在资源层中的 u2net.onnx 模型文件。管理模型运行所需的内存(准备输入 Tensor,接收输出 Tensor)。提供简洁的 JS API(如 InferenceSession.create(), session.run())供上层应用调用。最关键的作用:根据浏览器支持情况和模型需求,智能选择并调度计算任务到下层的最佳执行引擎(首选通常是 WebAssembly)。
执行引擎层 (Runtime Backends):
onnxruntime-web实际执行模型计算的地方。
WebAssembly (Wasm) 后端是核心加速引擎:
u2net 模型的计算密集型操作(卷积、矩阵乘等)被编译成高效的 Wasm 字节码。Wasm 引擎在浏览器的安全沙箱中以接近原生代码的速度执行这些字节码。这是实现高性能浏览器内推理的关键,使得复杂的 u2net 模型能在用户设备上流畅运行。
WebGL 后端 (备选) :
利用 GPU 进行加速,特别适合 u2net 中大量使用的卷积操作。性能潜力高,但可能受浏览器兼容性、WebGL 精度限制和特定模型适配的影响。
(可选) WebNN 后端 (未来方向) :直接调用操作系统提供的底层 AI 硬件加速(如 NPU),潜力最大,但目前支持有限。
模型层 (U2Net 神经网络):
包含训练好的 u2net 模型,以 ONNX 格式 (.onnx 文件) 存储。ONNX 是一个开放的、框架无关的模型表示格式,使得 u2net 模型可以被 onnxruntime-web 加载和运行。这个文件包含了 u2net 独特的嵌套 U 型结构 (U^2-Net) 的定义以及训练得到的所有权重参数。它定义了具体的抠图任务如何执行。
资源层 (Browser Environment):
提供模型文件 u2net.onnx 的来源(通过 HTTP 下载、存储在 IndexedDB 或利用 Cache API)。提供运行时环境:浏览器内置的 WebAssembly 引擎负责执行 Wasm 字节码,WebGL API 用于 GPU 加速,WebNN API (如果可用) 用于底层硬件加速。提供硬件计算资源:用户的 CPU (用于运行 Wasm)、GPU (用于 WebGL)、潜在的专用 AI 处理器 NPU/APU (用于 WebNN)。
源代码解析
Github:github.com/yuedud/aicu…
目录解析
public
public是存放静态资源的地方,存储了onnx模型和一些静态的资源图片
src
src是核心代码存放的地方,下面我们只来介绍一下关于抠图部分的代码,核心代码在src/components/ImageSegmentation.js
可以看到在进入网站之后,第一时间就开始加载模型,同时使用了indexedDB进行了模型缓存,二次使用的时候直接用indexedDB里获取模型,由于模型较大,所以加载时间会比较长。
// 加载模型
useEffect(() => {
const loadModel = async () => {
try {
setError(null);
const db = await openDB();
let modelData = await getModelFromDB(db);
if (modelData) {
console.log('从IndexedDB加载模型.');
} else {
console.log('IndexedDB中未找到模型,从网络下载...');
const response = await fetch('./u2net.onnx');
if (!response.ok) {
throw new Error(`网络请求模型失败: ${response.status} ${response.statusText}`);
}
modelData = await response.arrayBuffer();
console.log('模型下载完成,存入IndexedDB...');
await storeModelInDB(db, modelData);
console.log('模型已存入IndexedDB.');
}
const newSession = await ort.InferenceSession.create(modelData, {
executionProviders: ['wasm'], // 'webgl' 或 'wasm'
graphOptimizationLevel: 'all',
});
setSession(newSession);
console.log('ONNX模型加载并初始化成功');
} catch (e) {
console.error('ONNX模型加载或初始化失败:', e);
setError(`模型处理失败: ${e.message}`);
}
};
loadModel();
}, []);然后可以看到在上传完图片之后进行了图片的预处理,主要是将图片转换成了模型的入参Tensor
const preprocess = async (imgElement) => {
const canvas = document.createElement('canvas');
const modelWidth = 320;
const modelHeight = 320;
canvas.width = modelWidth;
canvas.height = modelHeight;
const ctx = canvas.getContext('2d');
ctx.drawImage(imgElement, 0, 0, modelWidth, modelHeight);
const imageData = ctx.getImageData(0, 0, modelWidth, modelHeight);
const data = imageData.data;
const float32Data = new Float32Array(1 * 3 * modelHeight * modelWidth);
const mean = [0.485, 0.456, 0.406];
const std = [0.229, 0.224, 0.225];
for (let i = 0; i < modelHeight * modelWidth; i++) {
float32Data[i] = (data[i * 4] / 255 - mean[0]) / std[0]; // R
float32Data[i + modelHeight * modelWidth] = (data[i * 4 + 1] / 255 - mean[1]) / std[1]; // G
float32Data[i + 2 * modelHeight * modelWidth] = (data[i * 4 + 2] / 255 - mean[2]) / std[2]; // B
}
return new ort.Tensor('float32', float32Data, [1, 3, modelHeight, modelWidth]);
};然后就是将模型的入参放到模型中去推理
const runSegmentation = async () => {
if (!image || !session) {
setError('请先上传图片并等待模型加载完成。');
return;
}
setError(null);
setOutputImage(null);
try {
const imgElement = imageRef.current;
if (!imgElement) {
throw new Error('图片元素未找到。');
}
// 确保图片完全加载
if (!imgElement.complete) {
await new Promise(resolve => { imgElement.onload = resolve; });
}
const inputTensor = await preprocess(imgElement);
const feeds = { 'input.1': inputTensor }; // 确保输入名称与模型一致
const results = await session.run(feeds);
const outputTensor = results[session.outputNames[0]];
const outputDataURL = postprocess(outputTensor, imgElement);
setOutputImage(outputDataURL);
} catch (e) {
console.error('抠图失败:', e);
setError(`抠图处理失败: ${e.message}`);
}
};当模型推理完之后,进行模型推理结果的后处理,主要是将alpha通道和原图片进行合成
// 后处理:将模型输出转换为透明背景图像
const postprocess = (outputTensor, originalImgElement) => {
const outputData = outputTensor.data;
const [height, width] = outputTensor.dims.slice(-2); // 通常是 [1, 1, H, W]
const canvas = document.createElement('canvas');
canvas.width = originalImgElement.naturalWidth; // 使用原始图片尺寸
canvas.height = originalImgElement.naturalHeight;
const ctx = canvas.getContext('2d');
// 1. 绘制原始图片
ctx.drawImage(originalImgElement, 0, 0, canvas.width, canvas.height);
const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
const pixelData = imageData.data;
// 2. 创建一个临时的canvas来处理和缩放mask
const maskCanvas = document.createElement('canvas');
maskCanvas.width = width; // U2Net输出mask的原始宽度
maskCanvas.height = height; // U2Net输出mask的原始高度
const maskCtx = maskCanvas.getContext('2d');
const maskImageData = maskCtx.createImageData(width, height);
// 归一化mask值 (通常U2Net输出在0-1之间,但最好检查一下)
let minVal = Infinity;
let maxVal = -Infinity;
for (let i = 0; i < outputData.length; i++) {
minVal = Math.min(minVal, outputData[i]);
maxVal = Math.max(maxVal, outputData[i]);
}
for (let i = 0; i < height * width; i++) {
let value = (outputData[i] - minVal) / (maxVal - minVal); // 归一化到 0-1
value = Math.max(0, Math.min(1, value)); // 确保在0-1范围内
const alpha = value * 255;
maskImageData.data[i * 4] = 0; // R
maskImageData.data[i * 4 + 1] = 0; // G
maskImageData.data[i * 4 + 2] = 0; // B
maskImageData.data[i * 4 + 3] = alpha; // Alpha
}
maskCtx.putImageData(maskImageData, 0, 0);
// 3. 将缩放后的mask应用到原始图像的alpha通道
// 创建一个新的canvas用于绘制最终结果,并将mask缩放到原始图像尺寸
const finalMaskCanvas = document.createElement('canvas');
finalMaskCanvas.width = originalImgElement.naturalWidth;
finalMaskCanvas.height = originalImgElement.naturalHeight;
const finalMaskCtx = finalMaskCanvas.getContext('2d');
finalMaskCtx.drawImage(maskCanvas, 0, 0, finalMaskCanvas.width, finalMaskCanvas.height);
const finalMaskData = finalMaskCtx.getImageData(0, 0, finalMaskCanvas.width, finalMaskCanvas.height);
for (let i = 0; i < pixelData.length / 4; i++) {
pixelData[i * 4 + 3] = finalMaskData.data[i * 4 + 3]; // 将mask的alpha通道应用到原始图片
}
ctx.putImageData(imageData, 0, 0);
return canvas.toDataURL();
};至此将合成的图片渲染到屏幕上就可以了。
如何启动
首先我们要对仓库进行克隆
git clone https://github.com/yuedud/aicut.git
然后安装依赖
npm install
然后直接启动项目
npm start
启动之后你就可以在本地尝试背景移除工具。
相关文章
广告赞助


热门文章
-
⛳前端进阶:SEO 全方位解决方案
2023-06-07 -
Claude Code完全指南:2025年最强AI编程助手深度评测
2025-06-06 -

提升前端SEO的技巧与方法
2024-08-04 -
别再吹通用型Al Agent了!其实真实业务都是Workflow
2025-04-28 -
Trae Pro 付费版来啦!🤔 你会掏钱吗?
2025-03-15 -
OCR识别常见的八大开源工具
2023-07-31 -

Vue 3.4 发布
2023-12-29 -
AI - 发现一个超级好用的 AI 聚合平台
2024-06-10
有话要说...